

DiverGen 使大規模實例分割訓練更加有效
:::info 作者:
(1) 范成祥,來自中國浙江大學,貢獻相同;
(2) 朱慕之,來自中國浙江大學,貢獻相同;
(3) 陳浩,中國浙江大學 (haochen.cad@zju.edu.cn);
(4) 劉揚,中國浙江大學;
(5) 吳偉嘉,中國浙江大學;
(6) 張華琪,vivo移動通信有限公司;
(7) 沈春華,中國浙江大學 (chunhuashen@zju.edu.cn)。
:::
目錄連結
摘要和1 引言
-
相關工作
-
我們提出的DiverGen
3.1. 數據分佈分析
3.2. 生成數據多樣性增強
3.3. 生成流程
-
實驗
4.1. 設置
4.2. 主要結果
4.3. 消融研究
-
結論、致謝和參考文獻
\ 附錄
A. 實現細節
B. 可視化
摘要
實例分割對數據需求量大,隨著模型容量增加,數據規模對提高準確性變得至關重要。如今大多數實例分割數據集需要昂貴的人工標註,限制了其數據規模。在這類數據上訓練的模型容易在訓練集上過擬合,尤其是對於那些稀有類別。雖然最近的工作已經深入研究利用生成模型創建合成數據集進行數據增強,但這些方法並未有效利用生成模型的全部潛力。
\ 為解決這些問題,我們引入了一種更有效的策略來構建用於數據增強的生成數據集,稱為DiverGen。首先,我們從分佈差異的角度解釋了生成數據的作用。我們研究了不同數據對模型學習分佈的影響。我們認為生成數據可以擴展模型可以學習的數據分佈,從而減輕過擬合。此外,我們發現生成數據的多樣性對提高模型性能至關重要,並通過各種策略增強它,包括類別多樣性、提示多樣性和生成模型多樣性。通過這些策略,我們可以將數據擴展到數百萬級,同時保持模型性能提升的趨勢。在LVIS數據集上,DiverGen顯著優於強大的模型X-Paste,在所有類別上實現了+1.1框AP和+1.1掩碼AP,對於稀有類別則實現了+1.9框AP和+2.5掩碼AP。我們的代碼可在https://github.com/aim-uofa/DiverGen獲取。
1. 引言
實例分割[2, 4, 9]是計算機視覺中具有挑戰性的任務之一,需要預測圖像中實例的掩碼和類別,這是許多視覺應用的基礎。隨著模型學習能力的提高,對訓練數據的需求增加了。然而,當前用於實例分割的數據集嚴重依賴人工標註,這既耗時又昂貴,且數據集規模無法滿足模型的訓練需求。儘管最近出現了自動標註的數據集SA-1B[12],但它缺乏類別標註,無法滿足實例分割的要求。同時,生成模型的持續發展大大提高了生成樣本的可控性和真實性。例如,最近的文本到圖像擴散模型[22, 24]可以生成與輸入提示相對應的高質量圖像。因此,當前方法[27, 28, 34]使用生成模型進行數據增強,通過生成數據集來補充模型在真實數據集上的訓練並提高模型性能。雖然當前方法已經提出了各種策略使生成數據提升模型性能,但仍存在一些限制:1) 現有方法尚未充分發揮生成模型的潛力。首先,一些方法[34]不僅使用生成數據,還需要從互聯網爬取圖像,這對獲取大規模數據是非常具有挑戰性的。同時,從互聯網爬取的數據內容不可控,需要額外檢查。其次,現有方法沒有充分利用生成模型的可控性。當前方法通常採用手動設計的模板來構建提示,限制了生成模型的潛在輸出。2) 現有方法[27, 28]通常從類別不平衡或數據稀缺的角度解釋生成數據的作用,而沒有考慮真實世界數據和生成數據之間的差異。此外,這些方法通常只在真實樣本數量有限的情況下顯示出改進的模型性能,而對於現有的大規模真實數據集(如LVIS[8])上生成數據的有效性尚未得到充分研究。
\ 在本文中,我們首先從分佈差異的角度探討生成數據的作用,解決兩個主要問題:1) 為什麼生成數據增強能提高模型性能? 2) 哪些類型的生成數據有利於提高模型性能?首先,我們發現有限真實訓練數據的模型學習分佈與真實世界數據分佈之間存在差異。我們對數據進行可視化,發現與真實世界數據相比,生成數據可以擴展模型可以學習的數據分佈。此外,我們發現添加生成數據的作用是減輕真實訓練數據的偏差,有效減輕對訓練數據的過擬合。其次,我們發現生成數據的分佈與真實世界數據分佈之間也存在差異。如果這些差異處理不當,就無法充分利用生成模型的潛力。通過進行多項實驗,我們發現使用多樣化的生成數據使模型能夠更好地適應這些差異,提高模型性能。
\ 基於上述分析,我們提出了一種有效的數據多樣性增強策略,即生成數據多樣性增強。我們設計了各種多樣性增強策略,從類別多樣性、提示多樣性和生成模型多樣性的角度增加數據多樣性。對於類別多樣性,我們觀察到使用覆蓋所有類別的生成數據訓練的模型比使用部分類別訓練的模型更能適應分佈差異。因此,我們不僅引入了LVIS[8]中的類別,還引入了ImageNet-1K[23]中的額外類別,以增強數據生成中的類別多樣性,從而增強模型對分佈差異的適應性。對於提示多樣性,我們發現隨著生成數據集規模的增加,手動設計的提示無法擴展到相應的水平,限制了生成模型輸出圖像的多樣性。因此,我們設計了一套多樣化的提示生成策略,使用大型語言模型(如ChatGPT)進行提示生成,要求大型語言模型在約束條件下輸出最大程度多樣化的提示。通過結合手動設計的提示和ChatGPT設計的提示,我們有效豐富了提示多樣性,進一步提高了生成數據多樣性。對於生成模型多樣性,我們發現來自不同生成模型的數據也表現出分佈差異。在訓練期間使模型接觸來自不同生成模型的數據可以增強對不同分佈的適應性。因此,我們分別使用Stable Diffusion[22]和DeepFloyd-IF[24]為所有類別生成圖像,並在訓練期間混合這兩種類型的數據以增加數據多樣性。
\ 同時,我們優化了數據生成工作流程,提出了一個由實例生成、實例標註、實例過濾和實例增強組成的四階段生成流程。在實例生成階段,我們採用我們提出的生成數據多樣性增強來提高數據多樣性,產生多樣化的原始數據。在實例標註階段,我們引入了一種稱為SAM-background的標註策略。該策略通過使用背景點作為SAM[12]的輸入提示,獲得高質量的標註,獲取原始數據的標註。在實例過濾階段,我們引入了一個稱為CLIP互相似度的指標。利用CLIP[21]圖像編碼器,我們提取生成數據和真實數據的嵌入,然後計算它們的相似度。較低的相似度表示較低的數據質量。過濾後,我們獲得最終的生成數據集。在實例增強階段,我們使用實例粘貼策略[34]來提高模型在生成數據上的學習效率。
\ 實驗表明,我們設計的數據多樣性策略可以有效提高模型性能,並在數據規模增加到百萬級時保持性能提升的趨勢,這使得大規模生成數據用於數據增強成為可能。在LVIS數據集上,DiverGen顯著優於強大的模型X-Paste[34],在所有類別上實現了+1.1框AP[8]和+1.1掩碼AP,對於稀有類別則實現了+1.9框AP和+2.5掩碼AP。
\ 總結來說,我們的主要貢獻如下:
\ • 我們從分佈差異的角度解釋了生成數據的作用。我們發現生成數據可以擴展模型可以學習的數據分佈,減輕對訓練集的過擬合,而生成數據的多樣性對提高模型性能至關重要。
\ • 我們提出了生成數據多樣性增強策略,從類別多樣性、提示多樣性和生成模型多樣性方面增加數據多樣性。通過增強數據多樣性,我們可以將數據擴展到數百萬級,同時保持模型性能提升的趨勢。
\ • 我們優化了數據生成流程。我們提出了一種SAM-background標註策略,以獲得更高質量的標註。我們還引入了一個稱為CLIP互相似度的過濾指標,用於過濾數據並進一步提高生成數據集的質量。
2. 相關工作
實例分割。實例分割是計算機視覺領域中的一項重要任務,已被廣泛研究。與語義分割不同,實例分割不僅在像素級別對像素進行分類,還區分同一類別的不同實例。以前,實例分割研究的重點主要是模型結構的設計。Mask-RCNN[9]統一了目標檢測和實例分割任務。隨後,Mask2Former[4]通過利用DETR[2]的結構,進一步統一了語義分割和實例分割任務。
\ 與這些專注於模型架構的研究正交,我們的工作主要研究如何更好地利用生成數據進行此任務。我們專注於具有挑戰性的
\ 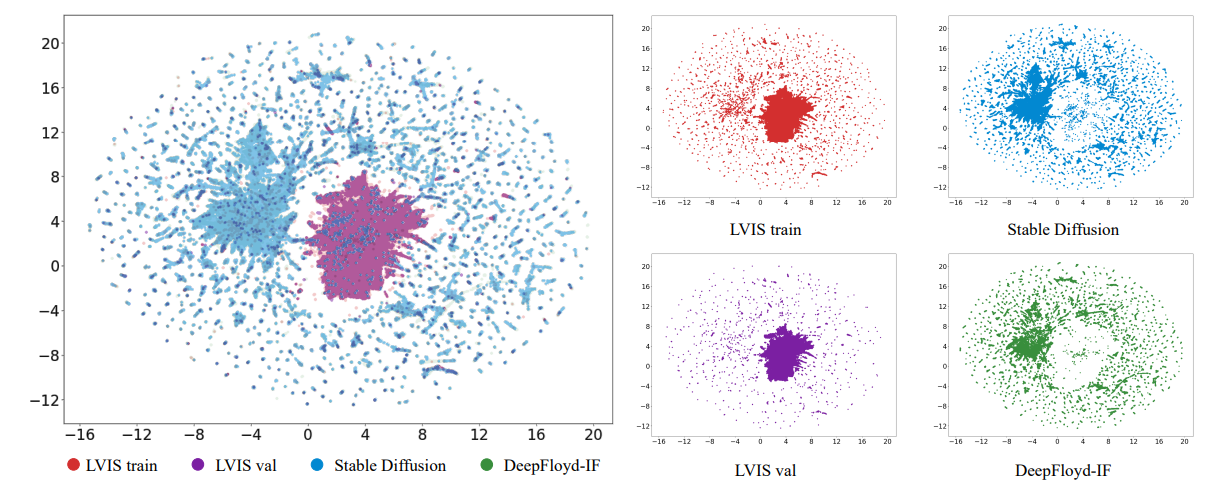
\ 長尾數據集LVIS[8],因為只有長尾類別面臨有限真實數據的問題,需要生成圖像進行增強,這使其更具實際意義。
\ 生成數據增強。使用生成模型合成訓練數據以輔助分類[6, 32]、檢測[3, 34
您可能也會喜歡

Uniswap 大戶在"UNIfication"漲幅達44%時拋售7500萬美元UNI – 內部人士退場還是巧合?

Grayscale 在 10 筆資金流入後擴展 Solana ETF 增加期權交易
