

使用自適應批次處理讓您的資料管道速度提升 5 倍
您的資料轉換流程中是否有大量的 LLM 呼叫?
CocoIndex 可能能夠幫助您。它由超高效能的 Rust 引擎提供支援,現在還支援開箱即用的自適應批次處理。這已經為 AI 原生工作流程提高了吞吐量約 5 倍(運行時間快約 80%)。最棒的是,您不需要更改任何程式碼,因為批次處理會自動進行,適應您的流量並保持 GPU 完全利用。
以下是我們在為 Cocoindex 構建自適應批次處理支援時學到的內容。
但首先,讓我們回答一些您可能想知道的問題。
為什麼批次處理能加速處理?
-
每次呼叫的固定開銷:這包括實際計算開始前所需的所有準備和管理工作。例如 GPU 核心啟動設置、Python 到 C/C++ 的轉換、任務排程、記憶體分配和管理,以及框架執行的記帳工作。這些開銷任務在很大程度上與輸入大小無關,但每次呼叫都必須全額支付。
\
-
與資料相關的工作:計算的這部分直接隨著輸入的大小和複雜性而擴展。它包括模型執行的浮點運算(FLOPs)、跨記憶體層次結構的資料移動、令牌處理和其他特定於輸入的操作。與固定開銷不同,這種成本與處理的資料量成正比增加。
當項目被單獨處理時,固定開銷會重複發生在每個項目上,這可能會迅速主導總運行時間,特別是當每個項目的計算相對較小時。相比之下,批次處理多個項目可以顯著降低每個項目受到的開銷影響。批次處理允許固定成本分攤到許多項目上,同時還能啟用硬體和軟體優化,提高與資料相關工作的效率。這些優化包括更有效地利用 GPU 管道、更好的快取利用率和更少的核心啟動,所有這些都有助於提高吞吐量並降低整體延遲。
\
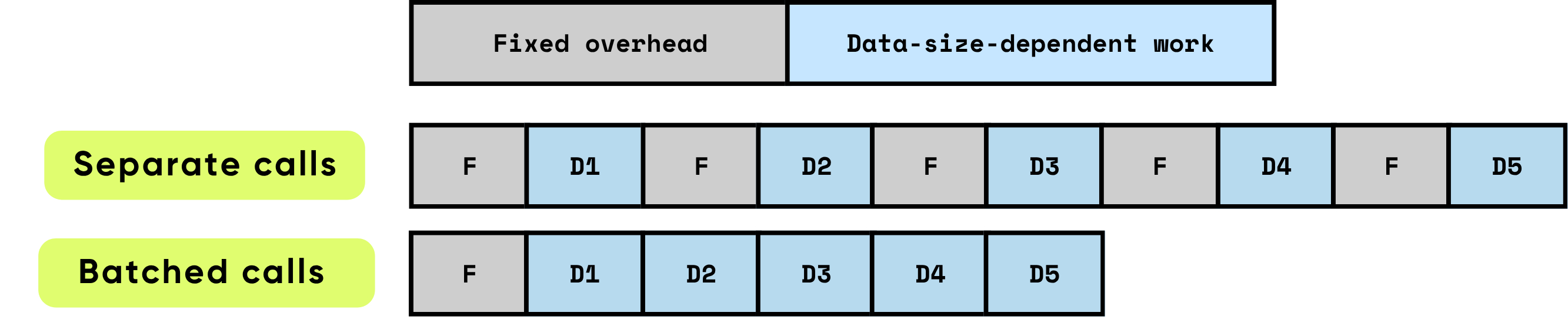
\ 批次處理通過優化計算效率和資源利用率顯著提高了性能。它提供多種疊加的好處:
\
-
分攤一次性開銷:每個函數或 API 呼叫都帶有固定開銷 — GPU 核心啟動、Python 到 C/C++ 的轉換、任務排程、記憶體管理和框架記帳。通過批次處理項目,這種開銷分散到許多輸入上,大幅降低了每個項目的成本並消除了重複的設置工作。
\
-
最大化 GPU 效率:較大的批次允許 GPU 執行密集、高度並行的矩陣乘法運算,通常實現為通用矩陣-矩陣乘法(GEMM)。這種映射確保硬體以更高的利用率運行,充分利用並行計算單元,最小化閒置週期,並實現峰值吞吐量。小型、非批次操作會使 GPU 大部分處於未充分利用狀態,浪費昂貴的計算能力。
\
-
減少資料傳輸開銷:批次處理最小化了 CPU(主機)和 GPU(設備)之間的記憶體傳輸頻率。較少的主機到設備(H2D)和設備到主機(D2H)操作意味著花在移動資料上的時間更少,而用於實際計算的時間更多。這對於高吞吐量系統至關重要,因為記憶體頻寬通常成為限制因素,而非原始計算能力。
結合起來,這些效果導致吞吐量有數量級的提升。批次處理將許多小型、低效的計算轉變為大型、高度優化的操作,充分利用現代硬體能力。對於 AI 工作負載 — 包括大型語言模型、電腦視覺和即時資料處理 — 批次處理不僅是一種優化;它對於實現可擴展的生產級性能至關重要。
\
普通 Python 程式碼中的批次處理是什麼樣子
非批次處理程式碼 – 簡單但效率較低
組織管道最自然的方式是逐個處理資料。例如,像這樣的兩層循環:
for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: vector = model.encode([chunk.text]) # one item at a time index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
這很容易閱讀和理解:每個塊直接流經多個步驟。
手動批次處理 – 更高效但更複雜
您可以通過批次處理來加速它,但即使是最簡單的「一次批次處理所有內容」版本也會使程式碼變得更加複雜:
\
# 1) Collect payloads and remember where each came from batch_texts = [] metadata = [] # (file_id, chunk_id) for file in os.listdir(directory): content = file.read() chunks = split_into_chunks(content) for chunk in chunks: batch_texts.append(chunk.text) metadata.append((file.name, chunk.offset)) # 2) One batched call (library will still mini-batch internally) vectors = model.encode(batch_texts) # 3) Zip results back to their sources for (file_name, chunk_offset), vector in zip(metadata, vectors): index.upsert(file_id=file.name, chunk_offset=chunk.offset, vector=vector)
此外,一次批次處理所有內容通常不是理想的,因為下一步只能在此步驟完成所有資料後才能開始。
CocoIndex 的批次處理支援
CocoIndex 彌合了差距,讓您能夠兩全其美 – 通過遵循自然流程保持程式碼的簡潔性,同時獲得 CocoIndex 運行時提供的批次處理效率。
我們已經為以下內建函數啟用了批次處理支援:
- EmbedText
- SentenceTransformerEmbed
- ColPaliEmbedImage
- ColPaliEmbedQuery
它不會改變 API。您現有的程式碼將無需任何更改即可運行 – 仍然遵循自然流程,同時享受批次處理的效率。
對於自定義函數,啟用批次處理非常簡單:
- 在自定義函數裝飾器中設置
batching=True。 - 將參數和返回類型更改為
list。
例如,如果您想創建一個調用 API 為圖像構建縮略圖的自定義函數。
@cocoindex.op.function(batching=True) def make_image_thumbnail(self, args: list[bytes]) -> list[bytes]: ...
:::tip 查看批次處理文檔以獲取更多詳細信息。
:::
CocoIndex 如何進行批次處理
常見方法
批次處理的工作原理是將傳入請求收集到隊列中,並決定將它們作為單個批次刷新的最佳時機。這個時機至關重要 — 如果處理得當,您可以同時平衡吞吐量、延遲和資源使用。
兩種廣泛使用的批次處理策略主導著這一領域:
- 基於時間的批次處理(每 W 毫秒刷新一次):在這種方法中,系統會刷新在固定 W 毫秒窗口內到達的所有請求。
-
優點:任何請求的最大等待時間是可預測的,實現也很直接。它確保即使在低流量期間,請求也不會無限期地留在隊列中。
-
缺點:在稀疏流量期間,閒置請求會緩慢累積,為早期到達的請求增加延遲。此外,最佳窗口 W 通常隨工作負載特性而變化,需要仔細調整以在延遲和吞吐量之間取得適當平衡。
\
- 基於大小的批次處理(當隊列中有 K 個項目時刷新):在這裡,一旦隊列達到預定義的項目數量 K,就會觸發批次處理。
- 優點:批次大小是可預測的,這簡化了記憶體管理和系統設計。很容易推斷每個批次將消耗的資源。
- 缺點:當流量較輕時,請求可能會在隊列中停留較長時間,增加最先到達項目的延遲。與基於時間的批次處理一樣,最佳 K 取決於工作負載模式,需要經驗調整。
許多高性能系統採用混合方法:當時間窗口 W 到期或隊列達到大小 K 時(以先發生者為準)刷新批次。這種策略捕捉了兩種方法的優點,在稀疏流量期間提高響應性,同時在高峰負載期間保持高效的批次大小。
儘管如此,批次處理總是涉及可調參數和權衡。流量模式、工作負載特性和系統限制都會影響理想設置。實現最佳性能通常需要監控、分析和動態調整這些參數,以符合實時條件。
CocoIndex 的方法
框架層面:自適應,無需調節
CocoIndex 實現了一種簡單而自然的批次處理機制,可自動適應傳入的請求負載。該過程如下:
\
- 連續排隊:當當前批次在設備(例如 GPU)上處理時,任何新傳入的請求不會立即處理。相反,它們被排隊。這允許系統在不中斷正在進行的計算的情況下累積工作。
- 自動批次窗口:當當前批次完成時,CocoIndex 立即取隊列中已累積的所有請求並將它們視為下一個批次。這組請求形成新的批次窗口。然後系統立即開始處理這個批次。
- 自適應批次處理:沒有計時器,沒有固定的批次大小,也沒有預配置的閾值。每個批次的大小自然適應於前一個批次服務時間內到達的流量。高流量期間自動產生較大的批次,最大化 GPU 利用率。低流量期間
您可能也會喜歡

4,057,686 SHIB 在數日內被銷毀:還剩下什麼?

PEPE 價格預測 2025-2031:Pepe 幣會在 2025 年主導 Dogecoin 和 Shiba Inu 嗎?
