

Future of GAL: Dynamic Filtering Strategies and Generative Model in the Loop
Table of Links
Abstract and 1 Introduction
-
Related work
2.1. Generative Data Augmentation
2.2. Active Learning and Data Analysis
-
Preliminary
-
Our method
4.1. Estimation of Contribution in the Ideal Scenario
4.2. Batched Streaming Generative Active Learning
-
Experiments and 5.1. Offline Setting
5.2. Online Setting
-
Conclusion, Broader Impact, and References
\
A. Implementation Details
B. More ablations
C. Discussion
D. Visualization
C. Discussion
C.1. Comparing with existing methods
\ We’ve drawn the Table 11, analyzing our setting compared to previous active learning or generative data filtration methods. We’ve conducted analysis from aspects of data scale, whether it’s oriented towards downstream tasks, label quality, labeling costs, and whether there exists domain difference (between generated and real data).
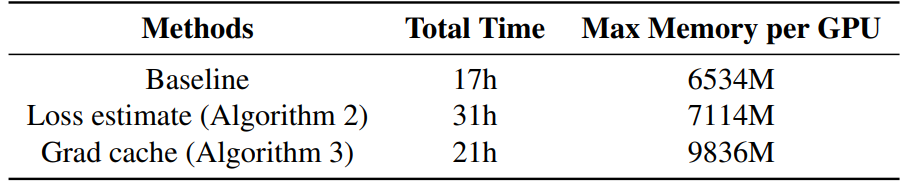
C.2. Analysis of the computational cost
We recorded the training duration and GPU memory usage for training 90,000 iterations with 4 Nvidia 4090 GPUs. It can be observed that our method based on Grad cache increases the GPU memory usage compared to Loss estimate, but it significantly reduces the training time. Compared with our Baseline, the additional time and memory overheads are within an acceptable range.
\ 
C.3. Future work
We hope that this paper can provide more inspiration to the academic community on how to utilize generated data and how to design better data analysis methods. It should be pointed out that our method is not limited to specific tasks or specific model architectures. In this work, for the convenience of comparison with the baseline, we use the same dataset and model architecture as the baseline. We hope that in future work, we can further verify it on more tasks and model architectures. At the same time, we can also design more flexible and controllable evaluation functions to better utilize generated data. For example, in this paper, when filtering the data with a gradient, there is a trade-off between diversity and consistency. For rare categories in the data, due to the small number of real data itself, diversity should be considered more, while for common categories, due to the large number of real data itself, consistency should be considered more. Therefore, in the future, we can consider adopting a dynamic strategy for different categories. In the long run, our current research is done under the premise of a fixed generative model. A more ideal situation is to involve the generative model in this loop, further optimizing the generative model based on the downstream model’s feedback, to achieve a true “generative model in the loop”.
\
:::info Authors:
(1) Muzhi Zhu, with equal contribution from Zhejiang University, China;
(2) Chengxiang Fan, with equal contribution from Zhejiang University, China;
(3) Hao Chen, Zhejiang University, China (haochen.cad@zju.edu.cn);
(4) Yang Liu, Zhejiang University, China;
(5) Weian Mao, Zhejiang University, China and The University of Adelaide, Australia;
(6) Xiaogang Xu, Zhejiang University, China;
(7) Chunhua Shen, Zhejiang University, China (chunhuashen@zju.edu.cn).
:::
:::info This paper is available on arxiv under CC BY-NC-ND 4.0 Deed (Attribution-Noncommercial-Noderivs 4.0 International) license.
:::
\
Ayrıca Şunları da Beğenebilirsiniz

TrendX Taps Trusta AI to Develop Safer and Smarter Web3 Network

Nvidia wants to boost H200 chip production to appease China
