

本節定義了一個新的、實用的實例增量學習(Instance-Incremental Learning,IIL)問題設定,專注於已部署系統中的成本效益模型提升。本節定義了一個新的、實用的實例增量學習(Instance-Incremental Learning,IIL)問題設定,專注於已部署系統中的成本效益模型提升。
新的 IIL 設定:僅使用新數據增強已部署模型
2025/11/05 23:00
連結目錄
摘要和1 引言
-
相關工作
-
問題設定
-
方法論
4.1. 決策邊界感知蒸餾
4.2. 知識鞏固
-
實驗結果和5.1. 實驗設置
5.2. 與最先進方法的比較
5.3. 消融研究
-
結論和未來工作及參考文獻
\
補充材料
- IIL中KCEMA機制理論分析的詳細信息
- 演算法概述
- 數據集詳情
- 實現細節
- 灰塵輸入圖像的可視化
- 更多實驗結果
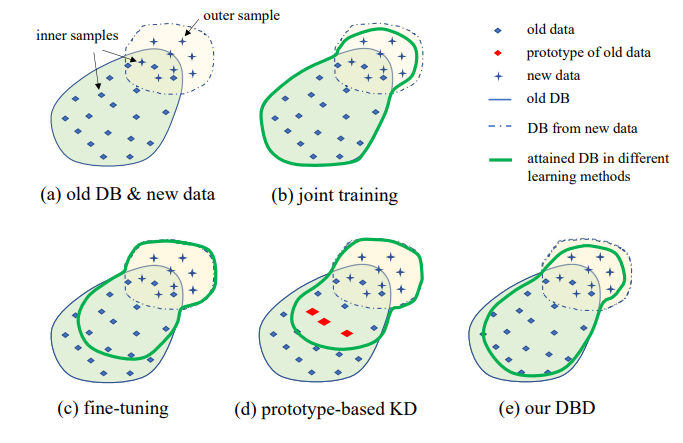
3. 問題設定
所提出的IIL設定的說明如圖1所示。如圖所示,數據在數據流中持續且不可預測地生成。通常在實際應用中,人們傾向於先收集足夠的數據並訓練一個強大的模型M0進行部署。無論模型多麼強大,它都不可避免地會遇到分佈外數據並在其上失敗。這些失敗案例和其他低分新觀察將被標註,以便不時地訓練模型。每次使用所有累積數據重新訓練模型會導致時間和資源成本越來越高。因此,新的IIL旨在每次僅使用新數據來增強現有模型。
\ 
\ 
\
:::info 作者:
(1) 聶強,香港科技大學(廣州);
(2) 付偉福,騰訊優圖實驗室;
(3) 林宇歡,騰訊優圖實驗室;
(4) 李嘉林,騰訊優圖實驗室;
(5) 周一峰,騰訊優圖實驗室;
(6) 劉勇,騰訊優圖實驗室;
(7) 聶強,香港科技大學(廣州);
(8) 王成傑,騰訊優圖實驗室。
:::
:::info 本論文可在arxiv上獲取,遵循CC BY-NC-ND 4.0 Deed(署名-非商業性使用-禁止演繹4.0國際)許可證。
:::
\
免責聲明: 本網站轉載的文章均來源於公開平台,僅供參考。這些文章不代表 MEXC 的觀點或意見。所有版權歸原作者所有。如果您認為任何轉載文章侵犯了第三方權利,請聯絡 service@support.mexc.com 以便將其刪除。MEXC 不對轉載文章的及時性、準確性或完整性作出任何陳述或保證,並且不對基於此類內容所採取的任何行動或決定承擔責任。轉載材料僅供參考,不構成任何商業、金融、法律和/或稅務決策的建議、認可或依據。
分享文章
您可能也會喜歡

從 FG Wallet 參與競賽
FG Wallet 是一個去中心化的自我託管錢包,允許在 Tron (TRC-20) 網絡上發送 USDT,而無需在您的餘額中持有 TRX。該錢包自動支付燃料費,並直接從 USDT 中扣除佣金。由於其專有技術,交易成本比其他錢包最多降低了 50%。主要優勢 [...] Сообщение 參與來自 FG Wallet 的競賽 появились сначала на INCRYPTED。
分享
Incrypted2025/11/06 05:50

2025 年第四季度 10 個成長最快的加密貨幣項目
加密貨幣市場可能難以預測,但數據會留下線索,顯示每個加密項目的表現。在第四季度 […] 這篇文章《2025年第四季度10個成長最快的加密項目》首次發表於Coindoo。
分享
Coindoo2025/11/06 05:45

狗狗幣價格預測:Elon Musk 準備將 DOGE 發射到真正的月球 – 這會是推動至 $1 的催化劑嗎?
DOGE-1 月球任務在 Elon Musk 的確認下即將進行 - Dogecoin 價格預測現在瞄準 $1,迎來其最大催化劑。
分享
Coinstats2025/11/06 07:06