

Extracție semantică cu set deschis: Pipeline Grounded-SAM, CLIP și DINOv2

Tabel de Linkuri
Rezumat și 1 Introducere
-
Lucrări Conexe
2.1. Navigare bazată pe Viziune și Limbaj
2.2. Înțelegerea Semantică a Scenei și Segmentarea Instanțelor
2.3. Reconstrucția Scenei 3D
-
Metodologie
3.1. Colectarea Datelor
3.2. Informații Semantice Open-set din Imagini
3.3. Crearea Reprezentării 3D Open-set
3.4. Navigare Ghidată prin Limbaj
-
Experimente
4.1. Evaluare Cantitativă
4.2. Rezultate Calitative
-
Concluzie și Lucrări Viitoare, Declarație de Divulgare și Referințe
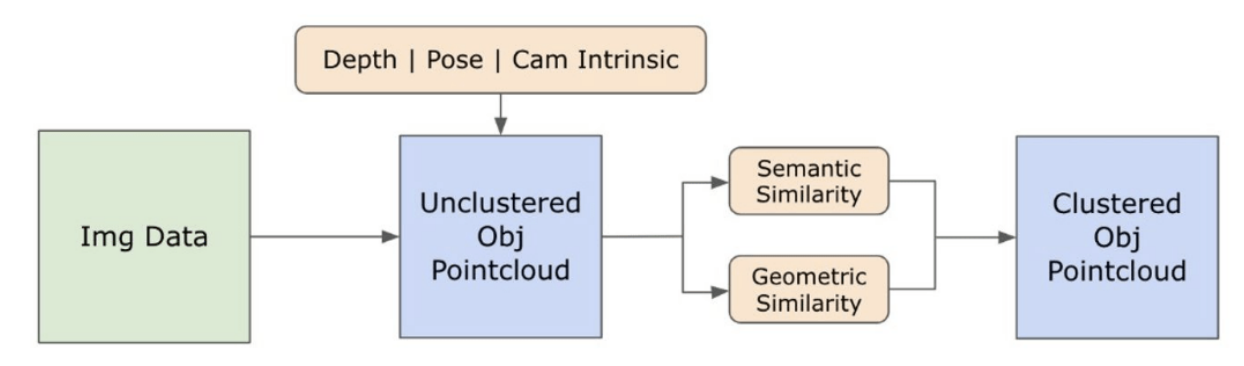
3.2. Informații Semantice Open-set din Imagini
\ 3.2.1. Detectarea Măștilor Semantice și de Instanță Open-set
\ Modelul Segment Anything (SAM) [21] lansat recent a câștigat o popularitate semnificativă în rândul cercetătorilor și practicienilor industriali datorită capacităților sale de segmentare de ultimă generație. Cu toate acestea, SAM tinde să producă un număr excesiv de măști de segmentare pentru același obiect. Adoptăm modelul Grounded-SAM [32] pentru metodologia noastră pentru a aborda această problemă. Acest proces implică generarea unui set de măști în trei etape, așa cum este ilustrat în Figura 2. Inițial, un set de etichete text este creat folosind modelul Recognizing Anything (RAM) [33]. Ulterior, casetele de delimitare corespunzătoare acestor etichete sunt create folosind modelul Grounding DINO [25]. Imaginea și casetele de delimitare sunt apoi introduse în SAM pentru a genera măști de segmentare agnostice la clasă pentru obiectele văzute în imagine. Oferim o explicație detaliată a acestei abordări mai jos, care atenuează eficient problema supra-segmentării prin încorporarea perspectivelor semantice din RAM și Grounding-DINO.
\ Modelul RAM [33] procesează imaginea RGB de intrare pentru a produce etichetarea semantică a obiectului detectat în imagine. Este un model fundamental robust pentru etichetarea imaginilor, demonstrând o capacitate remarcabilă de zero-shot în identificarea precisă a diverselor categorii comune. Rezultatul acestui model asociază fiecare imagine de intrare cu un set de etichete care descriu categoriile de obiecte din imagine. Procesul începe cu accesarea imaginii de intrare și convertirea acesteia în spațiul de culoare RGB, apoi redimensionarea pentru a se potrivi cerințelor de intrare ale modelului și, în final, transformarea acesteia într-un tensor, făcând-o compatibilă cu analiza modelului. În urma acestui proces, modelul RAM generează etichete sau tag-uri care descriu diversele obiecte sau caracteristici prezente în imagine. Se utilizează un proces de filtrare pentru a rafina etichetele generate, care implică eliminarea claselor nedorite din aceste etichete. În mod specific, tag-uri irelevante precum "perete", "podea", "tavan" și "birou" sunt eliminate, împreună cu alte clase predefinite considerate inutile pentru contextul studiului. În plus, această etapă permite augmentarea setului de etichete cu orice clase necesare care nu au fost inițial detectate de modelul RAM. În final, toate informațiile pertinente sunt agregate într-un format structurat. În mod specific, fiecare imagine este catalogată în dicționarul img_dict, care înregistrează calea imaginii împreună cu setul de etichete generate, asigurând astfel un depozit accesibil de date pentru analize ulterioare.
\ După etichetarea imaginii de intrare cu etichete generate, fluxul de lucru progresează prin invocarea modelului Grounding DINO [25]. Acest model se specializează în conectarea frazelor textuale la regiuni specifice dintr-o imagine, delimitând efectiv obiectele țintă cu casete de delimitare. Acest proces identifică și localizează spațial obiectele din imagine, punând bazele pentru analize mai granulare. După identificarea și localizarea obiectelor prin casete de delimitare, este utilizat modelul Segment Anything (SAM) [21]. Funcția principală a modelului SAM este de a genera măști de segmentare pentru obiectele din aceste casete de delimitare. Făcând acest lucru, SAM izolează obiectele individuale, permițând o analiză mai detaliată și specifică obiectului prin separarea efectivă a obiectelor de fundalul lor și între ele în cadrul imaginii.
\ În acest moment, instanțele obiectelor au fost identificate, localizate și izolate. Fiecare obiect este identificat cu diverse detalii, inclusiv coordonatele casetei de delimitare, un termen descriptiv pentru obiect, probabilitatea sau scorul de încredere al existenței obiectului exprimat în logiți și masca de segmentare. În plus, fiecare obiect este asociat cu caracteristici de încorporare CLIP și DINOv2, detalii care sunt elaborate în subsecțiunea următoare.
\ 3.2.2. Extragerea Încorporării Semantice
\ Pentru a îmbunătăți înțelegerea noastră a aspectelor semantice ale instanțelor de obiecte care au fost segmentate și mascate în imaginile noastre, folosim două modele, CLIP [9] și DINOv2 [10], pentru a deriva reprezentările caracteristicilor din imaginile decupate ale fiecărui obiect. Un model antrenat exclusiv cu CLIP realizează o înțelegere semantică robustă a imaginilor, dar nu poate discerne adâncimea și detaliile complexe din acele imagini. Pe de altă parte, DINOv2 demonstrează performanțe superioare în percepția adâncimii și excelează în identificarea relațiilor nuanțate la nivel de pixel între imagini. Ca un Transformer de Viziune auto-supervizat, DINOv2 poate extrage detalii nuanțate ale caracteristicilor fără a se baza pe date adnotate, făcându-l deosebit de eficient în identificarea relațiilor spațiale și a ierarhiilor din imagini. De exemplu, în timp ce modelul CLIP ar putea avea dificultăți în diferențierea între două scaune de culori diferite, cum ar fi roșu și verde, capacitățile DINOv2 permit ca astfel de distincții să fie făcute clar. În concluzie, aceste modele captează atât caracteristicile semantice, cât și vizuale ale obiectelor, care sunt utilizate ulterior pentru comparații de similaritate în spațiul 3D.
\ 
\ Un set de pași de pre-procesare este implementat pentru procesarea imaginilor cu modelul DINOv2. Acestea includ redimensionarea, decuparea centrală, convertirea imaginii într-un tensor și normalizarea imaginilor decupate delimitate de casetele de delimitare. Imaginea procesată este apoi introdusă în modelul DINOv2 împreună cu etichetele identificate de modelul RAM pentru a genera caracteristicile de încorporare DINOv2. Pe de altă parte, când se lucrează cu modelul CLIP, pasul de pre-procesare implică transformarea imaginii decupate într-un format tensor compatibil cu CLIP, urmat de calculul caracteristicilor de încorporare. Aceste încorporări sunt critice, deoarece încapsulează atributele vizuale și semantice ale obiectelor, care sunt cruciale pentru o înțelegere cuprinzătoare a obiectelor din scenă. Aceste încorporări sunt supuse normalizării bazate pe norma lor L2, care ajustează vectorul de caracteristici la o lungime unitară standardizată. Acest pas de normalizare permite comparații consistente și echitabile între diferite imagini.
\ În faza de implementare a acestei etape, iterăm prin fiecare imagine din datele noastre și executăm procedurile ulterioare:
\ (1) Imaginea este decupată la regiunea de interes folosind coordonatele casetei de delimitare furnizate de modelul Grounding DINO, izolând obiectul pentru o analiză detaliată.
\ (2) Generăm încorporări DINOv2 și CLIP pentru imaginea decupată.
\ (3) În final, încorporările sunt stocate împreună cu măștile din secțiunea anterioară.
\ Cu acești pași finalizați, acum posedăm reprezentări detaliate ale caracteristicilor pentru fiecare obiect, îmbogățind setul nostru de date pentru analiză și aplicare ulterioară.
\
:::info Autori:
(1) Laksh Nanwani, Institutul Internațional de Tehnologia Informației, Hyderabad, India; acest autor a contribuit în mod egal la această lucrare;
(2) Kumaraditya Gupta, Institutul Internațional de Tehnologia Informației, Hyderabad, India;
(3) Aditya Mathur, Institutul Internațional de Tehnologia Informației, Hyderabad, India; acest autor a contribuit în mod egal la această lucrare;
(4) Swayam Agrawal, Institutul Internațional de Tehnologia Informației, Hyderabad, India;
(5) A.H. Abdul Hafez, Universitatea Hasan Kalyoncu, Sahinbey, Gaziantep, Turcia;
(6) K. Madhava Krishna, Institutul Internațional de Tehnologia Informației, Hyderabad, India.
:::
:::info Această lucrare este disponibilă pe arxiv sub licența CC by-SA 4.0 Deed (Atribuire-Distribuire în condiții identice 4.0 Internațional).
:::
\
Poate îți place și
Taurii XRP câștigă încredere pe măsură ce sentimentul social devine pozitiv
![[Două Perspective] Mi-a făcut destinul meu să ajung cu același tip de femeie de fiecare dată?](https://www.rappler.com/tachyon/2025/12/two-pronged-2-Factor-Authentication-relationship.jpg)
[Două Perspective] Mi-a făcut destinul meu să ajung cu același tip de femeie de fiecare dată?
