

Matting robusto guiado por máscara: gerir entradas ruidosas e versatilidade de objetos
Tabela de Links
Abstrato e 1. Introdução
-
Trabalhos Relacionados
-
MaGGIe
3.1. Matting de Instância Guiado por Máscara Eficiente
3.2. Consistência Temporal Feature-Matte
-
Conjuntos de Dados de Matting de Instância
4.1. Matting de Instância de Imagem e 4.2. Matting de Instância de Vídeo
-
Experiências
5.1. Pré-treino em dados de imagem
5.2. Treino em dados de vídeo
-
Discussão e Referências
\ Material Suplementar
-
Detalhes da arquitetura
-
Matting de imagem
8.1. Geração e preparação do conjunto de dados
8.2. Detalhes do treino
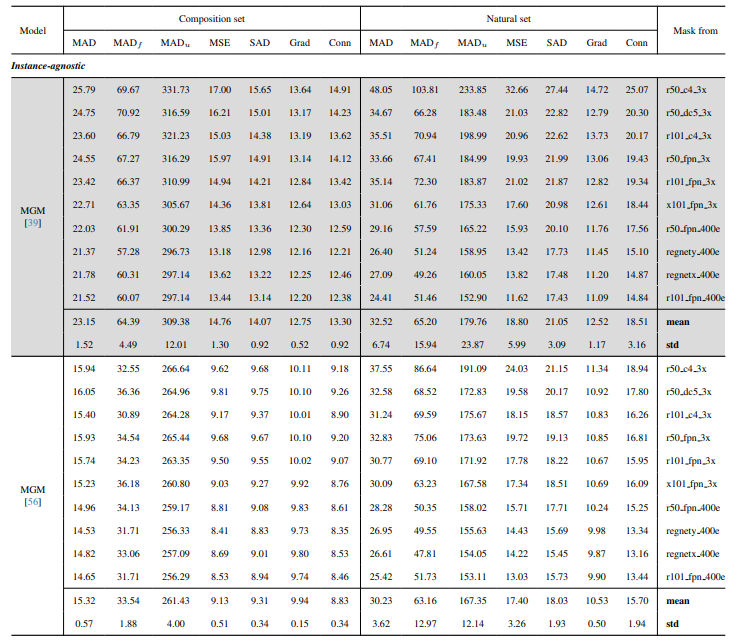
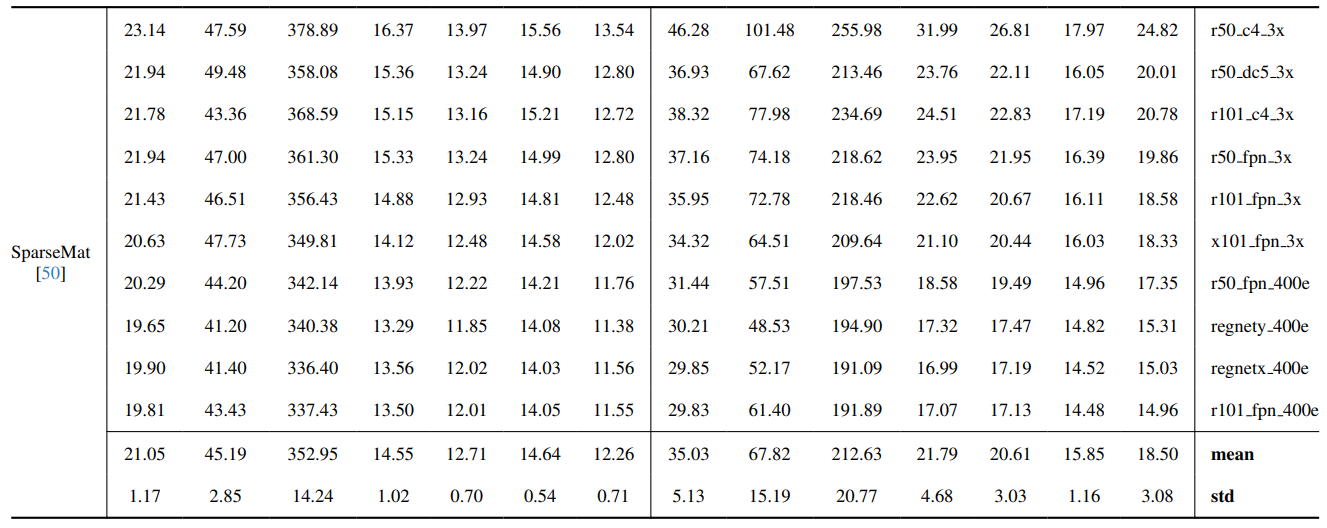
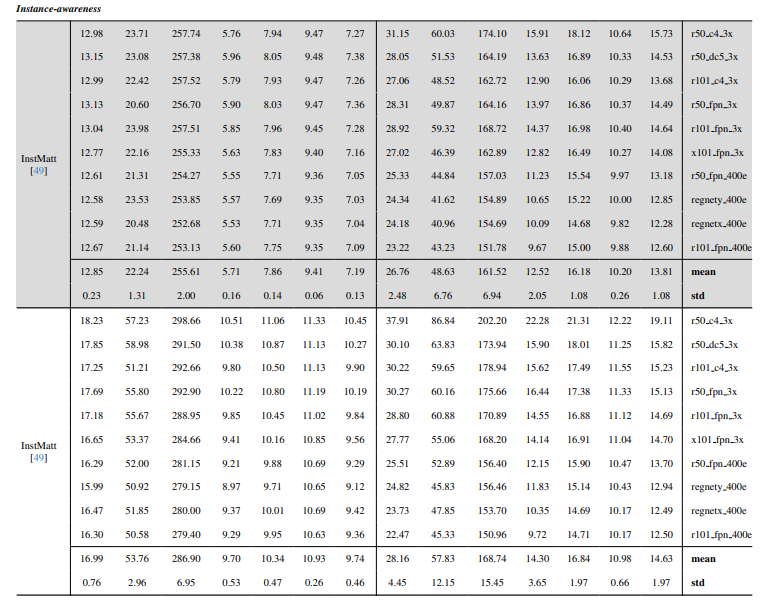
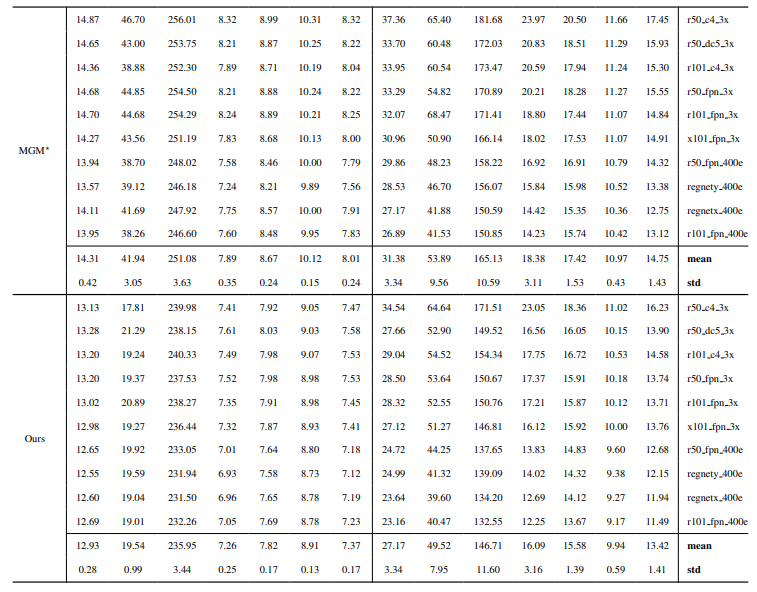
8.3. Detalhes quantitativos
8.4. Mais resultados qualitativos em imagens naturais
-
Matting de vídeo
9.1. Geração do conjunto de dados
9.2. Detalhes do treino
9.3. Detalhes quantitativos
9.4. Mais resultados qualitativos
8.4. Mais resultados qualitativos em imagens naturais
A Fig. 13 demonstra o desempenho do nosso modelo em cenários desafiantes, particularmente na renderização precisa de regiões de cabelo. A nossa framework supera consistentemente o MGM⋆ na preservação de detalhes, especialmente em interações complexas de instâncias. Em comparação com o InstMatt, o nosso modelo apresenta separação de instâncias superior e precisão de detalhes em regiões ambíguas.
\ A Fig. 14 e a Fig. 15 ilustram o desempenho do nosso modelo e trabalhos anteriores em casos extremos envolvendo múltiplas instâncias. Enquanto o MGM⋆ tem dificuldades com ruído e precisão em cenários de instâncias densas, o nosso modelo mantém alta precisão. O InstMatt, sem dados de treino adicionais, apresenta limitações nestas configurações complexas.
\ A robustez da nossa abordagem guiada por máscara é ainda mais demonstrada na Fig. 16. Aqui, destacamos os desafios enfrentados pelas variantes MGM e SparseMat na previsão de partes ausentes nas entradas de máscara, que o nosso modelo resolve. No entanto, é importante notar que o nosso modelo não foi concebido como uma rede de segmentação de instâncias humanas. Como mostrado na Fig. 17, a nossa framework adere à orientação de entrada, garantindo previsão precisa de alpha matte mesmo com múltiplas instâncias na mesma máscara.
\ Por fim, a Fig. 12 e a Fig. 11 enfatizam as capacidades de generalização do nosso modelo. O modelo extrai com precisão tanto sujeitos humanos como outros objetos dos fundos, demonstrando a sua versatilidade em vários cenários e tipos de objetos.
\ Todos os exemplos são imagens da Internet sem ground-truth e a máscara do r101fpn400e é usada como orientação.
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\ 
\
:::info Autores:
(1) Chuong Huynh, University of Maryland, College Park (chuonghm@cs.umd.edu);
(2) Seoung Wug Oh, Adobe Research (seoh,jolee@adobe.com);
(3) Abhinav Shrivastava, University of Maryland, College Park (abhinav@cs.umd.edu);
(4) Joon-Young Lee, Adobe Research (jolee@adobe.com).
:::
:::info Este artigo está disponível no arxiv sob licença CC by 4.0 Deed (Attribution 4.0 International).
:::
\


Você também pode gostar
Folha de Pagamento Não Agrícola dos EUA em Março: Recuperação Crítica para Previsão de 60K Após Tropeço de Fevereiro

Jimuel Pacquiao enfrenta veterano de MMA na sua 2.ª luta profissional




