

The Creation of ArSyTa, a Novel 8.27-Million-Context Dataset for Local Citation Recommendation
Table of Links
Abstract and 1. Introduction
-
Related Work
-
Proposed Dataset
-
SymTax Model
4.1 Prefetcher
4.2 Enricher
4.3 Reranker
-
Experiments and Results
-
Analysis
6.1 Ablation Study
6.2 Quantitative Analysis and 6.3 Qualitative Analysis
-
Conclusion
-
Limitations
-
Ethics Statement and References
Appendix
2 Related Work
Local citation recommendation has drawn comparatively less interest than its global counterpart until recently. He et al. (2010) introduced the task of local citation recommendation by using tf-idf based vector similarity between context and cited articles. Livne et al. (2014) extracted hand-crafted features from the citation excerpt and the remaining document text, and developed a system to recommend citations while the document is being drafted. The neural probabilistic model of (Huang et al., 2015) determines the citation probability for a given context by jointly embedding context and all articles in a shared embedding space. Ebesu and Fang (2017) proposed neural citation network based on encoder-decoder architecture. The encoder obtains a robust representation of citation context and further augments it via author networks and attention mechanism, which the decoder uses to generate the title of the cited paper. Dai et al. (2019) utilised stacked denoising autoencoders for representing cited articles, bidirectional LSTMs for citation context representation and attention principle over citation context to enhance the learning ability of their framework.
\ Jeong et al. (2020) proposed a BERT-GCN model which uses BERT (Kenton and Toutanova, 2019) to obtain embeddings for context sentences, and Graph Convolutional Network (Kipf and Welling, 2017) to derive embeddings from citation graph nodes. The two embeddings are then concatenated and passed through a feedforward neural network to obtain relevance between them. However, due to the high cost of computing GCN, as mentioned in Gu et al. (2022), BERT-GCN model was evaluated on tiny datasets containing merely a few thousand citation contexts. It highlights the limitation of scaling such GNN models for recommending citations on large datasets.
\ Medic and Šnajder (2020) suggested the use of global information of articles along with citation context to recommend citations. It computes semantic matching score between citation context and cited article text, and bibliographic score from the article’s popularity in the community to generate a final recommendation score. Ostendorff et al. (2022) perform neighbourhood contrastive learning over the full citation graph to yield citation embeddings and then uses k-nearest neighbourhood based indexing to retrieve the top recommendations. The most recent work in local citation recommendation by Gu et al. (2022) proposed a two-stage recommendation architecture comprising a fast prefetching module and a slow reranking module. We build upon work of Gu et al. (2022) by borrowing their prefetching module and designing a novel reranking module and another novel module named Enricher that fits between Prefetcher and Reranker. We name our model as SymTax (Symbiotic Relationship and Taxonomy Fusion).
\
3 Proposed Dataset
Motivation. Citation recommendation algorithms depend on the availability of the labelled data for training. However, curating such a dataset is challenging as full pdf papers must be parsed to extract citation excerpts and map the respective
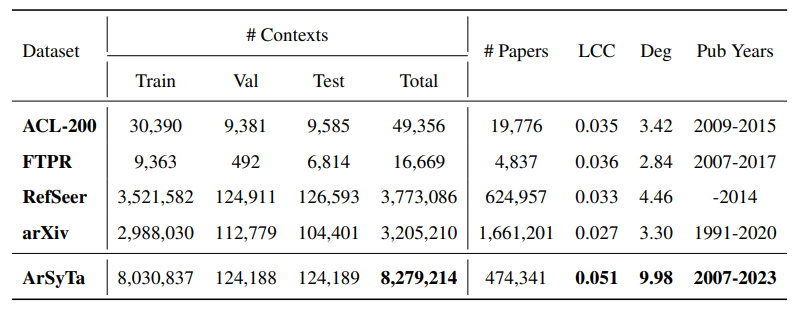
\ cited articles. Further, the constraint that cited articles should be present in the corpus eliminates a large proportion of it, thus reducing the dataset size considerably. e.g. FullTextPeerRead (Jeong et al., 2020) and ACL-200 (Medic and Šnajder, 2020) datasets contain only a few thousand papers and contexts. RefSeer (Medic and Šnajder, 2020) contains 0.6 million papers published till 2014 and hence is not up-to-date. Gu et al. (2022) released a large and recent arXiv-based dataset (we refer to it as arXiv(HAtten)) by following the same strategy adopted by ACL-200 and FullTextPeerRead for extracting contexts. They consider 200 characters around the citation marker as the citation context. The above mentioned datasets have limited features, which may restrict the design of new algorithms for local citation recommendation. Thus, we propose a novel dataset ArSyTa[3] which is latest, largest and contains rich citation contexts with additional features.
\ Dataset Creation. We selected 475, 170 papers belonging to Computer Science (CS) categories from over 1.7 million scholarly papers spanning STEM disciplines available on arXiv. The papers are selected from April 2007-January 2023 publication dates to ensure current relevance. arXiv contains an extensive collection of scientific papers that offer innate diversity in different formatting styles, templates and written characterisation, posing a significant challenge in parsing pdfs. We comprehensively evaluate established frameworks, namely, arXiv Vanity[4], CERMINE[5], and GROBID[6], for data extraction. arXiv Vanity converts pdfs to HTML format for data extraction but produces inconsistent results, thus turning extraction infeasible in this scenario. CERMINE uses JAVA binaries to generate BibTeX format from pdf but fails to extract many references, thereby not providing the required level of information. GROBID is a state-of-the-art tool that accurately and efficiently produces easy-to-parse results in XML format with a standard syntax. We conduct extensive manual testing to assess parsing efficacy and finally choose GROBID as it adeptly parses more than 99.99% (i.e., 474, 341) of the documents. We organise the constructed dataset into a directed graph. Nodes within the graph encapsulate a rich array of attributes, encompassing abstracts, titles, authors, submitters, publication dates, topics, categories within CS, and comments associated with each paper. Edges within graph symbolise citations, carrying citation contexts and section headings in which they appear. This provides a format that offers better visualisation and utilisation of data.
\ Unlike previously available datasets, which use a 200-character length window to extract citation context, we consider one sentence before and after the citation sentence as a complete citation context. We create a robust mapping function for efficient data retrieval. Since every citation does not contain a Digital Object Identifier, mapping citations to corresponding papers is challenging. The use of several citation formats and the grammatical errors adds a further challenge to the task. To expedite title-based searches that associate titles with unique paper IDs, we devise an approximate mapping function based on LCS (Longest Common Substring), but the sheer size of the number of papers makes it infeasible to run directly, as each query requires around 10 seconds. Finally, to identify potential matches, we employ an approximate hash function called MinHash LSH (Locality Sensitivity Hashing), which provides the top 100 candidates with a high probability for a citation existing in our raw database to be present in the candidate list. We then utilise LCS matching with a 0.9 similarity score threshold to give a final candidate, thus reducing the time to a few microseconds. Finally, our dataset consists of 8.27 million citation contexts whereas the largest existing dataset, RefSeer, consists of only 3.7 million contexts. The dataset is essentially comprised of contexts and the corresponding metadata only and not the research papers, as is the case with other datasets. Even after considering a relatively lesser number of papers as a raw source, we curated significantly more citation contexts (i.e.,final data), thus showing the effectiveness of our data extraction technique. This is further supported empirically by the fact that our dataset has significantly higher values of average local clustering coefficient and average degree with respect to the other datasets (as shown in Table 1). Each citing paper and cited paper that corresponds to a citation context respectively belongs to a CS concept in the flat-level arXiv taxonomy that contains 40 classes. The distribution of category classes in arXiv taxonomy for ArSyTa is shown in Figure 3 (Appendix).
\ Technical Merits. ArSyTa offers the following merits over the existing datasets: (i) As shown in Table 1, ArSyTa is 2.2x and 2.6x larger than RefSeer and arXiv(HAtten), respectively. Also, our citation context network is more dense than all other datasets, clearly showing that our dataset creation strategy is better. (ii) It is the most recent dataset that contains papers till January 2023. (iii) It contains longer citation contexts and additional signals such as section heading and document category. (iv) ArSyTa is suitable for additional scientific document processing tasks that can leverage section heading as a feature or a label. (v) ArSyTa is more challenging than others as it contains papers from different publication venues with varied formats and styles submitted to arXiv.
\
:::info Authors:
(1) Karan Goyal, IIIT Delhi, India (karang@iiitd.ac.in);
(2) Mayank Goel, NSUT Delhi, India (mayank.co19@nsut.ac.in);
(3) Vikram Goyal, IIIT Delhi, India (vikram@iiitd.ac.in);
(4) Mukesh Mohania, IIIT Delhi, India (mukesh@iiitd.ac.in).
:::
:::info This paper is available on arxiv under CC by-SA 4.0 Deed (Attribution-Sharealike 4.0 International) license.
:::
[3] ArSyTa: Arxiv Symbiotic Relationship Taxonomy Fusion
\ [4] https://github.com/arxiv-vanity/arxiv-vanity
\ [5] https://github.com/CeON/CERMINE
\ [6] https://github.com/kermitt2/grobidclientpython

You May Also Like

Top NYC Book Publishing Companies

Sensorion Announces its Participation in the Association for Research in Otolaryngology ARO 49th Annual Midwinter Meeting
