

استخراج الدلالات المفتوحة: خط أنابيب Grounded-SAM وCLIP وDINOv2
جدول الروابط
نبذة مختصرة و1 مقدمة
-
الأعمال ذات الصلة
2.1. التنقل بالرؤية واللغة
2.2. فهم المشهد الدلالي وتجزئة الكائنات
2.3. إعادة بناء المشهد ثلاثي الأبعاد
-
المنهجية
3.1. جمع البيانات
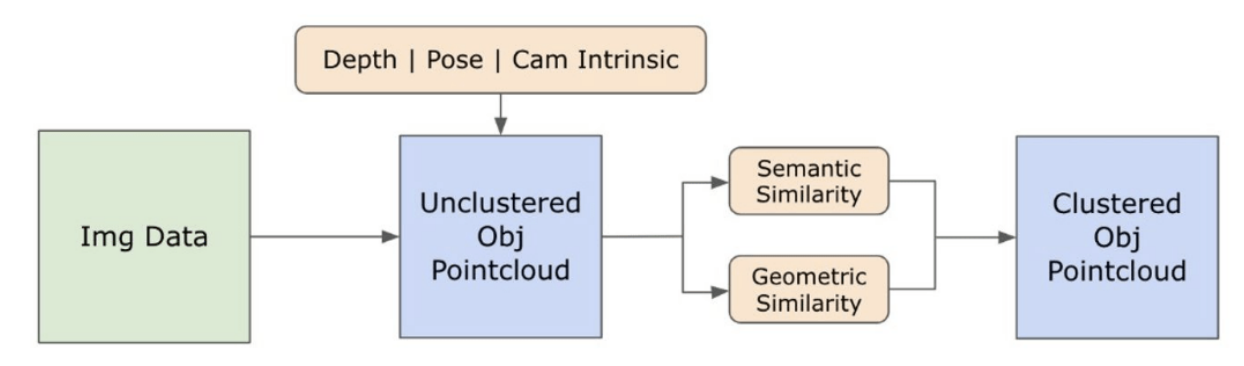
3.2. المعلومات الدلالية مفتوحة المجموعة من الصور
3.3. إنشاء تمثيل ثلاثي الأبعاد مفتوح المجموعة
3.4. التنقل الموجه باللغة
-
التجارب
4.1. التقييم الكمي
4.2. النتائج النوعية
-
الخلاصة والعمل المستقبلي، وبيان الإفصاح، والمراجع
3.2. المعلومات الدلالية مفتوحة المجموعة من الصور
\ 3.2.1. اكتشاف الأقنعة الدلالية والكائنات مفتوحة المجموعة
\ اكتسب نموذج Segment Anything (SAM) [21] الذي تم إصداره مؤخرًا شعبية كبيرة بين الباحثين والممارسين الصناعيين بسبب قدراته المتطورة في التجزئة. ومع ذلك، يميل SAM إلى إنتاج عدد مفرط من أقنعة التجزئة للكائن نفسه. نعتمد نموذج Grounded-SAM [32] في منهجيتنا لمعالجة هذه المشكلة. تتضمن هذه العملية إنشاء مجموعة من الأقنعة في ثلاث مراحل، كما هو موضح في الشكل 2. في البداية، يتم إنشاء مجموعة من التسميات النصية باستخدام نموذج Recognizing Anything (RAM) [33]. بعد ذلك، يتم إنشاء مربعات الحدود المقابلة لهذه التسميات باستخدام نموذج Grounding DINO [25]. ثم يتم إدخال الصورة ومربعات الحدود في SAM لإنشاء أقنعة تجزئة غير مصنفة للكائنات المرئية في الصورة. نقدم شرحًا مفصلاً لهذا النهج أدناه، والذي يخفف بشكل فعال من مشكلة التجزئة المفرطة من خلال دمج الرؤى الدلالية من RAM و Grounding-DINO.
\ يعالج نموذج RAM [33] صورة RGB المدخلة لإنتاج تسميات دلالية للكائن المكتشف في الصورة. إنه نموذج أساسي قوي لوضع علامات على الصور، ويظهر قدرة استثنائية على التعرف الفوري في تحديد مختلف الفئات الشائعة بدقة. يربط مخرجات هذا النموذج كل صورة مدخلة بمجموعة من التسميات التي تصف فئات الكائنات في الصورة. تبدأ العملية بالوصول إلى الصورة المدخلة وتحويلها إلى مساحة ألوان RGB، ثم يتم تغيير حجمها لتناسب متطلبات إدخال النموذج، وأخيرًا تحويلها إلى تنسور، مما يجعلها متوافقة مع التحليل بواسطة النموذج. بعد ذلك، ينتج نموذج RAM تسميات، أو علامات، تصف الكائنات أو الميزات المختلفة الموجودة داخل الصورة. يتم استخدام عملية ترشيح لتنقية التسميات المنشأة، والتي تتضمن إزالة الفئات غير المرغوب فيها من هذه التسميات. على وجه التحديد، يتم تجاهل العلامات غير ذات الصلة مثل "الجدار" و"الأرضية" و"السقف" و"المكتب"، إلى جانب فئات أخرى محددة مسبقًا تعتبر غير ضرورية لسياق الدراسة. بالإضافة إلى ذلك، تسمح هذه المرحلة بتعزيز مجموعة التسميات بأي فئات مطلوبة لم يتم اكتشافها في البداية بواسطة نموذج RAM. أخيرًا، يتم تجميع جميع المعلومات ذات الصلة في تنسيق منظم. على وجه التحديد، يتم فهرسة كل صورة داخل قاموس img_dict، الذي يسجل مسار الصورة إلى جانب مجموعة التسميات المنشأة، مما يضمن مستودعًا يمكن الوصول إليه للبيانات للتحليل اللاحق.
\ بعد وضع علامات على الصورة المدخلة بالتسميات المنشأة، يتقدم سير العمل من خلال استدعاء نموذج Grounding DINO [25]. يتخصص هذا النموذج في ربط العبارات النصية بمناطق محددة داخل الصورة، مما يحدد بشكل فعال الكائنات المستهدفة بمربعات الحدود. تحدد هذه العملية وتحدد مكان الكائنات داخل الصورة، مما يضع الأساس لتحليلات أكثر تفصيلاً. بعد تحديد وتحديد مكان الكائنات عبر مربعات الحدود، يتم استخدام نموذج Segment Anything (SAM) [21]. الوظيفة الأساسية لنموذج SAM هي إنشاء أقنعة تجزئة للكائنات داخل مربعات الحدود هذه. من خلال القيام بذلك، يعزل SAM الكائنات الفردية، مما يتيح تحليلًا أكثر تفصيلاً وخاصًا بالكائن من خلال فصل الكائنات بشكل فعال عن خلفيتها وعن بعضها البعض داخل الصورة.
\ في هذه المرحلة، تم تحديد وتحديد مكان وعزل حالات الكائنات. يتم تحديد كل كائن بتفاصيل مختلفة، بما في ذلك إحداثيات مربع الحدود، ومصطلح وصفي للكائن، واحتمالية أو درجة الثقة في وجود الكائن معبرًا عنها في اللوجيت، وقناع التجزئة. علاوة على ذلك، يرتبط كل كائن بميزات تضمين CLIP و DINOv2، والتي يتم توضيح تفاصيلها في القسم الفرعي التالي.
\ 3.2.2. استخراج التضمين الدلالي
\ لتحسين فهمنا للجوانب الدلالية لحالات الكائنات التي تم تجزئتها وتقنيعها داخل صورنا، نستخدم نموذجين، CLIP [9] و DINOv2 [10]، لاشتقاق تمثيلات الميزات من الصور المقتطعة لكل كائن. يحقق النموذج المدرب حصريًا باستخدام CLIP فهمًا دلاليًا قويًا للصور ولكنه لا يستطيع تمييز العمق والتفاصيل المعقدة داخل تلك الصور. من ناحية أخرى، يظهر DINOv2 أداءً متفوقًا في إدراك العمق ويتفوق في تحديد علاقات البكسل الدقيقة عبر الصور. كمحول رؤية ذاتي التعلم، يمكن لـ DINOv2 استخراج تفاصيل ميزات دقيقة دون الاعتماد على بيانات مشروحة، مما يجعله فعالًا بشكل خاص في تحديد العلاقات المكانية والتسلسلات الهرمية داخل الصور. على سبيل المثال، بينما قد يواجه نموذج CLIP صعوبة في التمييز بين كرسيين بألوان مختلفة، مثل الأحمر والأخضر، تسمح قدرات DINOv2 بإجراء مثل هذه التمييزات بوضوح. في الختام، تلتقط هذه النماذج كلاً من الميزات الدلالية والبصرية للكائنات، والتي تستخدم لاحقًا لمقارنات التشابه في الفضاء ثلاثي الأبعاد.
\ 
\ يتم تنفيذ مجموعة من خطوات المعالجة المسبقة لمعالجة الصور باستخدام نموذج DINOv2. تشمل هذه تغيير الحجم، والاقتصاص المركزي، وتحويل الصورة إلى تنسور، وتطبيع الصور المقتطعة المحددة بواسطة مربعات الحدود. ثم يتم تغذية الصورة المعالجة في نموذج DINOv2 جنبًا إلى جنب مع التسميات المحددة بواسطة نموذج RAM لإنشاء ميزات تضمين DINOv2. من ناحية أخرى، عند التعامل مع نموذج CLIP، تتضمن خطوة المعالجة المسبقة تحويل الصورة المقتطعة إلى تنسيق تنسور متوافق مع CLIP، يليها حساب ميزات التضمين. هذه التضمينات مهمة لأنها تلخص السمات البصرية والدلالية للكائنات، والتي تعد ضرورية للفهم الشامل للكائنات في المشهد. تخضع هذه التضمينات للتطبيع بناءً على معيار L2 الخاص بها، مما يعدل متجه الميزات إلى طول وحدة موحدة. تتيح خطوة التطبيع هذه مقارنات متسقة وعادلة عبر الصور المختلفة.
\ في مرحلة التنفيذ لهذه المرحلة، نقوم بالتكرار على كل صورة داخل بياناتنا وتنفيذ الإجراءات اللاحقة:
\ (1) يتم اقتصاص الصورة إلى منطقة الاهتمام باستخدام إحداثيات مربع الحدود المقدمة من نموذج Grounding DINO، مما يعزل الكائن للتحليل المفصل.
\ (2) إنشاء تضمينات DINOv2 و CLIP للصورة المقتطعة.
\ (3) أخيرًا، يتم تخزين التضمينات مرة أخرى مع الأقنعة من القسم السابق.
\ مع اكتمال هذه الخطوات، نمتلك الآن تمثيلات ميزات مفصلة لكل كائن، مما يثري مجموعة البيانات الخاصة بنا لمزيد من التحليل والتطبيق.
\
:::info المؤلفون:
(1) لاكش نانواني، المعهد الدولي لتكنولوجيا المعلومات، حيدر أباد، الهند؛ ساهم هذا المؤلف بشكل متساوٍ في هذا العمل؛
(2) كوماراديتيا جوبتا، المعهد الدولي لتكنولوجيا المعلومات، حيدر أباد، الهند؛
(3) أديتيا ماثور، المعهد الدولي لتكنولوجيا المعلومات، حيدر أباد، الهند؛ ساهم هذا المؤلف بشكل متساوٍ في هذا العمل؛
(4) سوايام أغراوال، المعهد الدولي لتكنولوجيا المعلومات، حيدر أباد، الهند؛
(5) أ.هـ. عبد الحافظ، جامعة حسن كاليونجو، شاهينبي، غازي عنتاب، تركيا؛
(6) ك. مادهافا كريشنا، المعهد الدولي لتكنولوجيا المعلومات، حيدر أباد، الهند.
:::
:::info هذه الورقة متاحة على arxiv تحت رخصة CC by-SA 4.0 Deed (الإسناد-المشاركة بالمثل 4.0 الدولية).
:::
\
قد يعجبك أيضاً

الذين فاتتهم فرصة XRP يتطلعون الآن إلى Apeing ($APEING) كواحدة من العملات الرقمية التالية التي ستصل إلى 1$ في 2025

هيئة الأوراق المالية والبورصات الأمريكية تصدر دليلاً حول حفظ العملات المشفرة للمستثمرين الأفراد
